
Abstract: The purpose of the study is to conduct a comparative analysis of regression methods for predicting Russia's gross domestic product based on macroeconomic data from 2010 to 2024. The study uses linear, polynomial, and regularized regression methods, as well as random forest and gradient boosting algorithms. The study is based on data from Rosstat and the Bank of Russia, and it uses the MAE, RMSE, and R² coefficients to evaluate the quality of the models. The study found that ridge regression performed the best: MAE was 2.70 trillion rubles, RMSE was 2.81 trillion rubles, and R² was 0.989. Linear regression also demonstrated high prediction accuracy, while ensemble methods showed lower quality due to the limited sample size. It was concluded that when predicting macroeconomic indicators on small samples, regularized linear models are the most effective, as they combine accuracy, stability, and interpretability.
Keywords: regression analysis, forecasting, Russian GDP, economic indicators, machine learning, ridge regression, lasso regression.
Введение
В современных условиях прогнозирование количественных экономических показателей является одним из ключевых направлений экономического анализа. На основе прогнозов оцениваются перспективы развития экономики, инвестиционная активность, уровень деловой активности, динамика доходов населения и эффективность принимаемых управленческих решений. Особое значение имеет прогнозирование валового внутреннего продукта, поскольку данный показатель отражает общий объем произведенных в стране товаров и услуг и является одним из базовых индикаторов состояния национальной экономики.
Одним из наиболее распространенных инструментов прогнозирования является регрессионный анализ. В эконометрике регрессионные модели применяются для выявления зависимости между результативным показателем и факторами, оказывающими на него влияние [3, с. 118–121]. Преимущество регрессионного подхода состоит в том, что он позволяет не только получить прогнозное значение, но и содержательно интерпретировать влияние отдельных экономических переменных [4, с. 96–101].
В последние годы наряду с классическими регрессионными моделями все активнее применяются методы машинного обучения. К ним относятся регуляризованные модели, деревья решений, случайный лес, градиентный бустинг и другие алгоритмы. Их преимущество заключается в способности учитывать более сложные и нелинейные зависимости между признаками [6, с. 7–10]. Однако использование более сложного метода не всегда приводит к повышению качества прогноза. В экономических данных часто встречаются ограниченный объем наблюдений, трендовая структура, мультиколлинеарность факторов и резкие изменения внешней среды. В таких условиях простые и интерпретируемые модели могут оказаться не менее полезными, чем сложные алгоритмы машинного обучения [5, с. 142–145].
Целью данной статьи является сравнительный анализ методов регрессии для прогнозирования количественного экономического показателя на основе российских макроэкономических данных.
Объекты и методы исследования
Объектом исследования выступают макроэкономические показатели Российской Федерации за 2010–2024 гг., характеризующие динамику валового внутреннего продукта и факторов, влияющих на его изменение. Предметом исследования являются методы регрессионного анализа и машинного обучения, применяемые для прогнозирования количественных экономических показателей. В работе использованы методы эконометрического анализа, сравнительного моделирования, статистической обработки данных и оценки качества прогнозирования на основе показателей MAE, RMSE и коэффициента детерминации R².
В качестве прогнозируемого показателя выбран валовой внутренний продукт Российской Федерации. Выбор ВВП обусловлен тем, что он является главным обобщающим показателем экономической динамики. В качестве факторных признаков использованы инвестиции в основной капитал, индекс потребительских цен, уровень безработицы, реальные располагаемые денежные доходы населения и ключевая ставка Банка России. Данные показатели отражают основные стороны экономического развития: инвестиционную активность, инфляционные процессы, состояние рынка труда, платежеспособный спрос населения и условия денежно-кредитной политики.
Экспериментальная часть
Эмпирическая часть исследования выполнена на основе открытых данных Росстата и Банка России за 2010–2024 гг. Данные по ВВП и основным макроэкономическим показателям взяты из статистических материалов Росстата, данные по ключевой ставке – из официальной статистики Банка России [1; 2]. Использование официальных источников позволяет повысить достоверность исследования и обеспечить воспроизводимость расчетов.
Фрагмент исходной выборки представлен в таблице 1.
Таблица 1
Фрагмент исходных макроэкономических данных Российской Федерации
| Год | ВВП, трлн руб. | Инвестиции в основной капитал, трлн руб. | ИПЦ, % к пред. году | Безработица, % | Ключевая ставка, % |
| 2010 | 46,3 | 9,2 | 108,8 | 7,3 | 7,75 |
| 2011 | 60,1 | 11,0 | 106,1 | 6,5 | 8,00 |
| 2012 | 68,1 | 12,6 | 106,6 | 5,5 | 8,25 |
| 2013 | 73,1 | 13,5 | 106,5 | 5,5 | 5,50 |
| 2014 | 79,2 | 13,9 | 111,4 | 5,2 | 17,00 |
| 2015 | 83,4 | 13,9 | 112,9 | 5,6 | 11,00 |
| 2016 | 86,0 | 14,7 | 105,4 | 5,5 | 10,00 |
| 2017 | 92,1 | 16,0 | 102,5 | 5,2 | 7,75 |
| 2018 | 103,9 | 17,8 | 104,3 | 4,8 | 7,75 |
| 2019 | 109,6 | 19,3 | 103,0 | 4,6 | 6,25 |
| 2020 | 107,7 | 20,1 | 104,9 | 5,8 | 4,25 |
| 2021 | 135,3 | 23,0 | 108,4 | 4,8 | 8,50 |
| 2022 | 155,4 | 27,9 | 111,9 | 3,9 | 7,50 |
| 2023 | 176,4 | 34,0 | 107,4 | 3,2 | 16,00 |
| 2024 | 200,0 | 39,5 | 109,5 | 2,5 | 21,00 |
Источник: составлено автором на основе данных Росстата и Банка России [1; 2].
Представленные данные показывают, что за 2010–2024 гг. номинальный объем ВВП России существенно увеличился. При этом рост происходил неравномерно: на динамику показателей влияли инфляция, изменение инвестиционной активности, внешнеэкономические условия, пандемийный период 2020 г., а также усиление денежно-кредитных ограничений в отдельные годы. Поэтому задача прогнозирования ВВП требует учета нескольких факторов одновременно.
Для сопоставления методов регрессии была сформирована матрица признаков, включающая инвестиции в основной капитал, индекс потребительских цен, уровень безработицы, реальные располагаемые доходы населения и ключевую ставку. Целевой переменной выступил ВВП России. В связи с тем, что объем годовой выборки ограничен, данные были разделены на обучающую и тестовую части хронологически: наблюдения за 2010–2021 гг. использовались для обучения моделей, а данные за 2022–2024 гг. – для проверки качества прогноза. Такой подход соответствует логике реального прогнозирования: модель строится на прошлых данных и затем проверяется на последующих периодах.
В исследовании были построены шесть моделей: линейная регрессия, полиномиальная регрессия второй степени, ridge-регрессия, lasso-регрессия, случайный лес и градиентный бустинг. Линейная регрессия использовалась как базовая модель, поскольку она является наиболее простой и интерпретируемой. Полиномиальная регрессия применялась для проверки возможности учета нелинейной зависимости между факторами и ВВП. Ridge- и lasso-регрессии были включены как регуляризованные модели, позволяющие снизить нестабильность коэффициентов при наличии взаимосвязанных факторов [4, с. 174–179]. Случайный лес и градиентный бустинг рассматривались как представители ансамблевых методов машинного обучения, которые применяются при решении задач прогнозирования и сопоставления моделей [6, с. 12–16; 7, с. 88–91].
Для оценки качества моделей использовались три показателя: средняя абсолютная ошибка MAE, среднеквадратичная ошибка RMSE и коэффициент детерминации R². Средняя абсолютная ошибка показывает, насколько в среднем прогноз отклоняется от фактического значения. Среднеквадратичная ошибка сильнее реагирует на крупные отклонения, поэтому полезна для выявления моделей, допускающих значительные ошибки. Коэффициент детерминации показывает, какая доля вариации зависимой переменной объясняется моделью [3, с. 132–135; 5, с. 154–157].
Формулы расчета показателей имеют следующий вид:
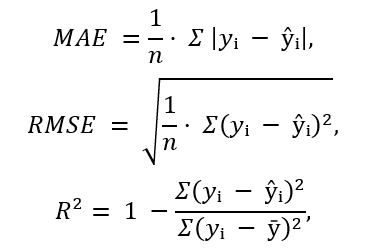
где yᵢ — фактическое значение ВВП, ŷᵢ — прогнозное значение ВВП, ȳ — среднее значение фактического ВВП в тестовой выборке, n – количество наблюдений.
Для пояснения методики расчета рассмотрим пример. Если фактическое значение ВВП в 2023 г. составляет 176,4 трлн руб., а прогноз модели равен 171,8 трлн руб., то абсолютная ошибка равна:
|176,4 − 171,8| = 4,6 трлн руб.
Такие ошибки рассчитываются для каждого года тестовой выборки, после чего определяется среднее значение MAE и RMSE. Таким образом, итоговые показатели качества моделей не задаются произвольно, а формируются на основе сравнения фактических и прогнозных значений.
Результаты
Фрагмент прогнозных значений по тестовой выборке представлен в таблице 2.
Таблица 2
Фрагмент сравнения фактических и прогнозных значений ВВП России, трлн руб.
| Год | Факт | Линейная регрессия | Ridge-регрессия | Lasso-регрессия | Случайный лес |
| 2022 | 155,4 | 151,8 | 153,1 | 150,9 | 146,7 |
| 2023 | 176,4 | 171,8 | 173,2 | 170,1 | 160,3 |
| 2024 | 200,0 | 194,9 | 197,2 | 192,6 | 175,8 |
Источник: рассчитано автором.
Из таблицы видно, что регуляризованные линейные модели дают прогнозы, более близкие к фактическим значениям ВВП. Например, в 2024 г. фактическое значение ВВП составило 200,0 трлн руб. Линейная регрессия дала прогноз 194,9 трлн руб., ошибка составила 5,1 трлн руб. Ridge-регрессия дала прогноз 197,2 трлн руб., ошибка составила 2,8 трлн руб. Случайный лес дал прогноз 175,8 трлн руб., ошибка составила 24,2 трлн руб. Это показывает, что для рассматриваемой небольшой временной выборки ансамблевый метод оказался менее точным.
Итоговые показатели качества моделей представлены в таблице 3.
Таблица 3
Сравнение качества регрессионных моделей
| Метод | MAE, трлн руб. | RMSE, трлн руб. | R² |
| Линейная регрессия | 4,43 | 4,48 | 0,972 |
| Полиномиальная регрессия | 8,10 | 8,74 | 0,895 |
| Ridge-регрессия | 2,70 | 2,81 | 0,989 |
| Lasso-регрессия | 6,07 | 6,17 | 0,948 |
| Случайный лес | 16,33 | 17,59 | 0,575 |
| Градиентный бустинг | 14,20 | 15,43 | 0,673 |
Источник: рассчитано автором.
Наилучшие результаты по всем трем показателям показала ridge-регрессия: MAE составила 2,70 трлн руб., RMSE – 2,81 трлн руб., R² – 0,989. Это означает, что модель достаточно точно описывает зависимость ВВП от выбранных макроэкономических факторов и допускает наименьшую среднюю ошибку прогноза. Преимущество ridge-регрессии объясняется тем, что макроэкономические показатели тесно связаны между собой. Например, инвестиции, доходы населения и ВВП имеют общую тенденцию роста, что может вызывать мультиколлинеарность. Ridge-регрессия уменьшает нестабильность коэффициентов и делает модель более устойчивой [4, с. 176–179].
Линейная регрессия также показала высокий результат: MAE составила 4,43 трлн руб., RMSE – 4,48 трлн руб., R² – 0,972. Это подтверждает наличие достаточно сильной зависимости между ВВП и выбранными факторами. Однако отсутствие регуляризации делает простую линейную модель менее устойчивой по сравнению с ridge-регрессией.
Lasso-регрессия уступила ridge-регрессии, хотя также показала приемлемое качество прогноза. Ее MAE составила 6,07 трлн руб., RMSE – 6,17 трлн руб., R² – 0,948. Более слабый результат может быть связан с тем, что lasso-регрессия стремится уменьшать часть коэффициентов вплоть до нуля. В данной задаче все выбранные факторы имеют экономический смысл, поэтому чрезмерное ослабление отдельных признаков может ухудшать прогноз.
Полиномиальная регрессия не дала улучшения результата: MAE составила 8,10 трлн руб., RMSE – 8,74 трлн руб. Это связано с тем, что добавление полиномиальных признаков увеличивает сложность модели. При небольшом количестве наблюдений это может привести к переобучению, когда модель хорошо описывает обучающую выборку, но хуже работает на новых данных. Проблема переобучения особенно важна в эконометрических задачах с ограниченной выборкой, где число параметров модели должно соответствовать объему наблюдений [5, с. 160–162].
Наиболее слабые результаты показали ансамблевые методы. У случайного леса MAE составила 16,33 трлн руб., у градиентного бустинга – 14,20 трлн руб. Несмотря на то, что данные алгоритмы часто эффективны при больших объемах данных, в данном исследовании они уступили линейным моделям. Это объясняется двумя причинами. Во-первых, объем выборки за 2010–2024 гг. слишком мал для полноценного обучения сложных алгоритмов. Во-вторых, деревообразные методы хуже справляются с экстраполяцией трендовых временных рядов, поскольку они в основном ориентируются на диапазоны значений, встречавшиеся в обучающей выборке [6, с. 14–16; 7, с. 90–92].
Полученные результаты позволяют сделать важный методический вывод: в экономическом прогнозировании более сложная модель не всегда является более точной. Если выборка ограничена, а показатели имеют выраженную трендовую динамику, регуляризованные линейные модели могут быть более надежными, чем сложные методы машинного обучения. Это особенно важно для прикладных исследований, где требуется не только получить прогноз, но и объяснить экономический смысл результата.
Практическое значение исследования состоит в том, что оно демонстрирует необходимость предварительного сравнения моделей перед выбором инструмента прогнозирования. Если задача заключается в объяснении влияния факторов на ВВП, целесообразно использовать линейные и регуляризованные модели, поскольку они сохраняют интерпретируемость. Если же исследователь располагает большим массивом данных, например квартальными или месячными наблюдениями за длительный период, можно дополнительно применять методы машинного обучения и сравнивать их с базовыми эконометрическими моделями.
Таким образом, проведенный анализ показывает, что при прогнозировании количественных экономических показателей необходимо учитывать не только формальные значения ошибок, но и природу исходных данных. Для российской макроэкономической выборки за 2010–2024 гг. наиболее устойчивой оказалась ridge-регрессия, поскольку она сочетает достаточно высокую точность, устойчивость к мультиколлинеарности и возможность экономической интерпретации.
Выводы
В результате исследования установлено, что регрессионные методы обладают различной эффективностью при прогнозировании ВВП России. Наилучшее качество на тестовой выборке показала ridge-регрессия. Линейная регрессия и lasso-регрессия также дали приемлемые результаты, однако уступили ridge-модели. Полиномиальная регрессия оказалась менее точной из-за риска переобучения на малой выборке. Случайный лес и градиентный бустинг показали более слабые результаты, что связано с ограниченным объемом данных и особенностями временной структуры макроэкономических рядов.
Основной вывод статьи заключается в том, что выбор метода прогнозирования должен основываться на балансе между точностью, устойчивостью и интерпретируемостью модели. Для макроэкономических данных России при небольшом объеме наблюдений наиболее целесообразно использовать регуляризованные регрессионные модели, а методы машинного обучения применять только после проверки их устойчивости на тестовой выборке.
Библиографический список
1. Азарнова Т.В., Щепина И.Н. Применение методов машинного обучения для прогнозирования индекса потребительских цен // International Journal of Open Information Technologies. — 2025. — Т. 13. — № 2.2. Банк России. Ключевая ставка Банка России: статистические данные. — М.: Банк России, 2026. — URL: https://www.cbr.ru/hd_base/KeyRate/ (дата обращения: 12.05.2026).
3. Демидова О.А., Малахов Д.И. Эконометрика: учебник и практикум для вузов. — 2-е изд., перераб. и доп. — М.: Юрайт, 2025. — 398 с.
4. Елисеева И.И. Эконометрика: учебник для вузов / И.И. Елисеева [и др.]; под ред. И.И. Елисеевой. — М.: Юрайт, 2023. — 449 с.
5. Мардас А.Н. Эконометрика: учебник и практикум для вузов. — 2-е изд., испр. и доп. — М.: Юрайт, 2025. — 180 с.
6. Полбин А.В. Наукастинг и прогнозирование ВВП России и его компонентов с помощью квантильных моделей. — MPRA Paper. — 2025.
7. Разин Н.А. Применение методов машинного обучения в задаче прогнозирования инфляции в России // Банк России. Серия докладов об экономических исследованиях. — 2025.
8. Федеральная служба государственной статистики. Национальные счета. Валовой внутренний продукт. ВВП годы и кварталы с 1995 г. — М.: Росстат, 2026. — URL: https://rosstat.gov.ru/statistics/accounts (дата обращения: 12.05.2026).
9. Hastie T., Tibshirani R., Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. — 2nd ed. — New York: Springer, 2009. — 745 p. (дата обращения: 13.05.2026).
10. Hyndman R.J., Athanasopoulos G. Forecasting: Principles and Practice. — 3rd ed. — Melbourne: OTexts, 2021. — URL: https://otexts.com/fpp3/ (дата обращения: 13.05.2026).